What is big data?
'Big Data' is a catch-all term for data that won't fit the usual containers. Big Data can be described in terms of:
- volume - too big to fit into a single server
- velocity -
streaming data, milliseconds to seconds to respond
- variety - data in many forms such as structured, unstructured, text, multimedia
The most difficult aspect of Big Data really involves its lack of structure. This lack of structure poses challenges because analysing the data is made significantly more difficult meaning machine learning techniques are
needed to discern patterns in the data and to extract useful information. It is also a problem because relational databases are not appropriate because they require the data to fit into a row-and-column format and relational
databases don't scale well when the data won’t fit on one server.
Velocity
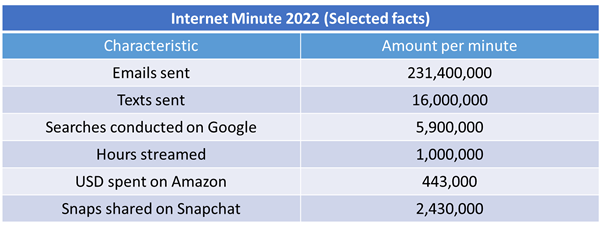
Data from networked sensors, smartphones, video surveillance, mouse clicks and more is continuously streamed. This generates a staggering amount of data. Below are some selected statsitics from the internet minute survey in
2022 which calculates the speed at which data is being generated.
Distributed systems
When data sizes are so big as not to fit on to a single server the processing must be distributed across more than one machine. Functional programming is a solution, because it makes it easier to write correct and efficient
distributed code that can be distributed to run across more than one server.
The reasons functional languages support this better are:
- They use immutable data structures: this means an objects state cant be changed once it is created so functions always return
the same result
- They are statelessness: Functions have no side effects so it does not matter how often or in what order they are called
- Functions are higher-order functions: A higher order function takes one or
more functions as a parameter and/or returns a function as a result
Fact based models
Each fact within a fact-based model for representing data captures a single piece of information. Immutable facts are recorded with timestamps. Data is never deleted, the data set continues to grow but the timestamps allow us
to discern what is current. Older data and the timestamps themselves are often not represented in a fact based model.
Graph schema are used for capturing the structure of a dataset. A graph schema is made up of nodes and edges each of which may have its own properties. A nodes properties may be shown inside the node as on the left below or
attached by dotted lines like on the right below. Relationships between nodes are shown as either directed or undirected arrow.
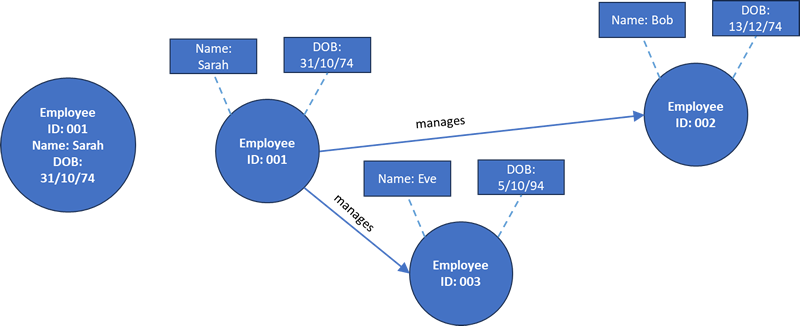
The benefits of fact based models are that new nodes and relationships can be added without affecting the existing data and where searching a relational database of a huge size takes a very long time with a fact based model
we can do this by finding our starting node and following the links.