Lossy and lossless compression
Lossy compression is where we reduce the size of a file by removing details we hope will not be noticed. This might mean reducing the number of different colours in an image. When lossy compression is used and the data is
reconstructed, it will not be the same as the original. Examples of lossy compression include .mp3 for sound and .jpg for images.
Lossless compression is where we reduce the size of a file by summarising runs of repeating data. This might mean recording frequency value pairs of the colour of a pixel and the number of pixels in a row that are that
colour. When lossless compression is used and the data is reconstructed, it will be identical to the original. Examples of lossless compression include .flac for sound, .gif for images and .zip for all files.
Certain files like text files, databases and program code cannot be compressed using lossy compression as losing any characters would render them unusable. Although lossless compression keeps the original file in tact, the
trade-off is that it does not compress the filesize as much as lossy compression.
Huffman encoding
Huffman encoding is a lossless compression method for text. It aims to reduce the filesize more by assigning the shortest binary codes to the most frequently occuring characters. You start by creating a table with the
frequencies of each chacater in the phrase to be compressed. In this example we are compressing the phrase 'ten tennis teens'.
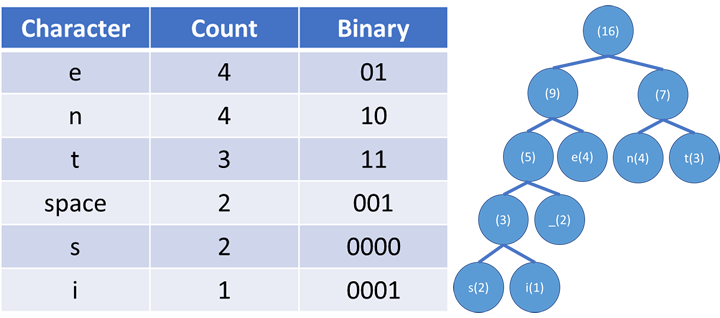
Compressed the phrase is: 1101100011101101000010000001110101100000. This is 40 bits or 8 bytes. In truth the huffman tree would also need to be sent but you don't need to consider that when considering filesize savings.
The same phrase in a bit ASCII would be 1 byte per character so 16 bytes. This means we made a saving of 11 bytes or a reduction of 68.75%