Character encoding
Computers can only understand binary. So when we want to store text on a computer it is stored as binary using a character set.
A character set is every character that can be represented by a computer using that character set and the equivalent binary value for that character. Below you can see the
7-bit ASCII character set.
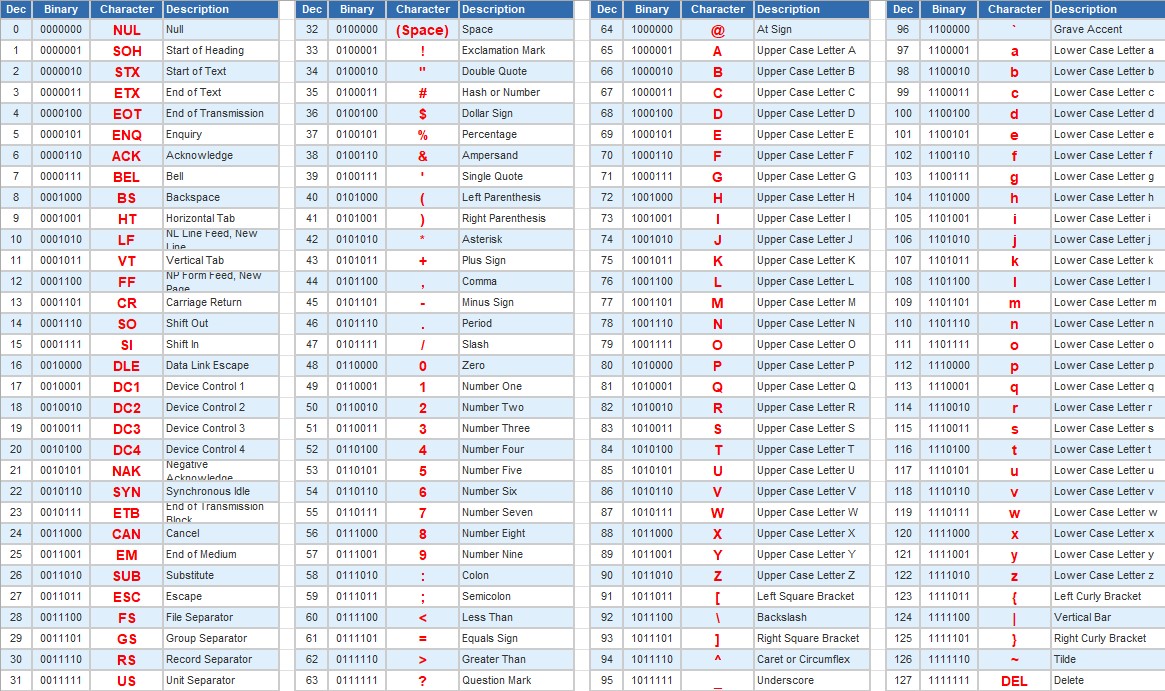
You don't need to know for instance that uppercase A is 65, but you should know that within the ASCII table groups of characters like the numbers, lowercase and uppercase
letters go in runs, so that if you were told that uppercase A was 65 you should be able to work out that uppercase E would be 69 as it is 4 letters further on.
ASCII and Unicode
ASCII stands for the American Standard Code for Information Interchange. The 7-bit ASCII character set shown above was an early character set. Because it uses 7 bits there
are 128 possible things that can be represented. Some of the first ASCII values are for special commands.
This was increased to 8-bit ASCII allowing for 256 characters so that some additional symbols from European languages, mathematics and more could be added. In 8-bit ASCII
the first 128 codes are the same as in 7-bit ASCII.
Unicode takes this a step further with either 16 or 32 bits. This is enough for all the languages in the world. It also provides spaces for new symbols like emojis.